I was working as a website developer in 2016. I worked on more than 100 sites in a span of 2 years. While developing or maintaining a website, clients always asked me one question: even though the website had been developed for a long time, the site was still not ranked & results are not shown in Google Search Webmaster Tool
Table of Contents
As the same question came up again and again, I decided to find an answer. I began conducting research.
I explored where website traffic originates, how it is generated, and who is responsible for driving it. I had many questions regarding the distinction between paid and organic traffic, and I set out to find answers to each of these inquiries.
While studying how to acquire traffic, I came across information about Google Search Webmaster Tool and decided to delve into this tool in depth.
What is Google Search Webmaster Tool?

It is a free tool created by the company Google. With its assistance, you can analyze the performance of the website on search engines. Problems on the webpage can also be resolved with the help of this tool.
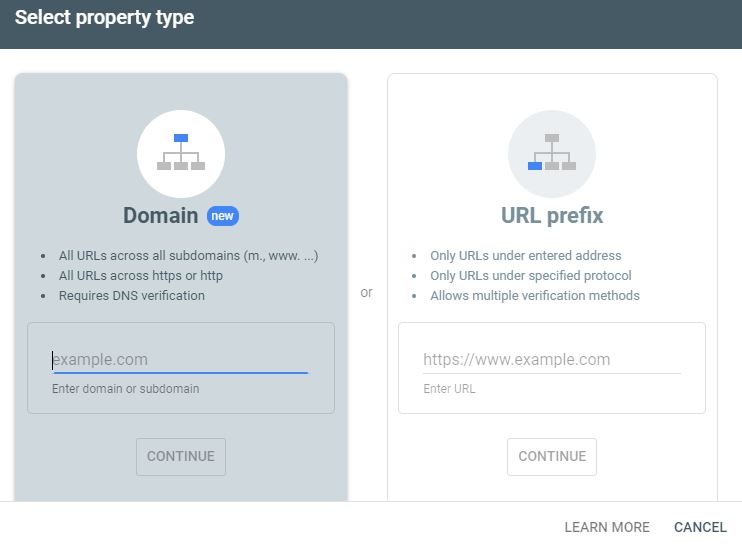
After creating a website, you need to connect it with the Webmaster tool. You can use either Domain or URL Prefix to add it.
Adding a site using a domain gives you the following:
- All URLs across all subdomains (m., www. …)
- All URLs across https or http
- Requires DNS verification
Adding a site using URL Prefix gives you the following:
- Only URLs under the entered address
- Only URLs under the specified protocol
- Allows multiple verification methods
Now, obtain the code and add it to the head section of the website. If you are unable to obtain the code, you will receive an HTML file, which should be uploaded to the root folder. Only the organic shares of your site will start appearing in Google Search Webmaster Tool, formerly known as Webmaster Tools.
Now you are in the tool’s panel. In the top left corner, you will see the Google Search Webmaster Tool logo. On the right side of it, there is an option to check the URL of the webpage. After entering any URL of your website, you will receive information about whether it has been crawled by Google’s webcrawler.
On the right side of the URL check, you will see an icon with a question mark in a circle, which is a help button. From there, you can get the information you need about the tool. Next to it is the user settings button. You can enter the user’s Gmail ID and grant them access to the console.
There is a notification bell on the right-hand side where you can see messages from Google regarding the tool. Finally, in the right corner, there is a button for Google Apps and user profile. Below that, you will find an Export button where you can download the report in Google Sheets, Excel, and CSV formats.
A list of domain names appears in the left sidebar of Google Search Webmaster Tool. Below that is the Overview section. In Overview, you can see the performance of the website. Under it, you can see the indexing section where you can find information about the total number of indexed and non-indexed webpages.
Below that is the experience section where you can view Core Web Vitals and HTTPS-related issues.
Following the experience section, you can find the Enhancements section. Here, you receive information about areas where you can improve the website. For example, you can check the placement of the breadcrumb, verify whether the FAQ page has been set up, and observe how the sitelink searchbox functions.
After that, the performance section follows. Here, we analyze where the traffic to the website is originating. It also indicates when the incoming traffic occurs and at what times it peaks. Traffic primarily comes through webpages, images, videos, and news. You can access data ranging from the nearest date up to a maximum of 16 months. Additionally, there is the option to specify a custom date, providing flexibility.
You can examine website traffic by query, page, country, and device. In each category, you can apply four types of filters: Queries containing, Queries not containing, Exact query, and Custom.
Moreover, there is an option for comparison. Within this feature, you can compare Queries containing, Queries not containing, Exact query, and Custom.
URL Inspection
We use URL Inspection when we need information about a specific page among the pages on the website. Copy the URL you want and paste it here.
After entering the URL, Google starts fetching the data from its index server, and within seconds, the data is available in front of you.
URL on Google
First of all, you get information about whether the URL is on Google. If the URL you provide is available on Google’s index server, it will show a green check mark. And if the URL is not available, it will say the URL is not on Google.
There, you will see an option called “View Crawled Page.” After clicking on it, you can understand how the page is ranked first by Google’s web crawler. It shows you the HTML code, screenshots, and some extra information.
If the page is not indexed, you can also request Google to index it. Additionally, you can take a live test of your page.
Page Indexing
In the bottom panel of Google Search Webmaster Tool, you get more information about indexed pages. The first section is “Discovery.”
Here, Google’s crawler understands where the page is taken from. You get information about which sitemap your page is taken from, and if there is a referring page, its link can also be seen here.
“Last crawl” shows the last day the page was crawled and the time at that time.
“Crawled as” indicates how Google’s web crawler understands your page. For example, Googlebot smartphone.
“Crawl allowed?” tells you whether the page is allowed or not.
“Page fetch” tells the status of crawling.
“Indexing allowed?” tells you whether the page will be displayed on Google or not.
In “User-declared canonical,” it is known if the developer has declared which is the original page.
Google itself decides if the developer has left out the Google-selected canonical.
Enhancements & Experience
The breadcrumb shows the path of the page. Page crawl-related information is available in its details.
Detected items provide more information about the breadcrumb schema, such as item list, item type, and item list element, etc.
Sitelinks search box provides information about the page’s search bar.
Detected items provide more information about the sitelinks search box schema, such as type, id, name, and URL.
Indexing
Page Indexing
Page indexing provides information about each of your pages. Get suggestions on which pages are performing well and what should be improved on those pages.
At first, you will see a dropdown where you can select the type of page you want to view.
All known pages mean all the pages Google crawler knows about within your domain. While browsing the Internet, Google stores every page of your website on its servers.
All submitted pages mean the pages that you tell Google to store on Google servers in any way. This includes sitemaps and manually submitted pages.
All unsubmitted pages mean the pages you have not submitted but the pages found by Google’s crawler under the domain. This also includes pages created by your developer by mistake.
/sitemap.xml means only those pages that are available in the website’s sitemap. If you don’t want to show any URL to Google crawler other than the sitemap, then you can use the robots.txt file.
Now after selecting the option, you can see the pages divided into two types: Not Indexed and Indexed in the first section. Here you also understand the reason why those are not indexed.
The second section explains why pages are not indexed. Some of the important reasons are as follows –
Not found (404)
Alternate page with proper canonical tag
Blocked by robots.txt
Page with redirect
Server error (5xx)
Blocked due to other 4xx issue
Duplicate without user-selected canonical
Excluded by ‘noindex’ tag
Soft 404
Duplicate, Google chose different canonical than user
Crawled – currently not indexed
Discovered – currently not indexed
Its next section is ‘Improve Page Appearance.’
It shows pages that you can modify to increase performance. You can improve the page as follows:
Indexed, though blocked by robots.txt
Page indexed without content
Video Indexing
As you can see, the first two sections apply to all pages, and you can also observe them in the video pages. Therefore, we will not discuss those things again here.
The second section explaining why pages are not indexed has some different points as follows:
Video is not the main content of the page
Video not processed yet
Video not processed
Video outside the viewport
Cannot determine video position and size
No thumbnail URL provided
Video is too small

